There are many different ways to store and relate your data in the power platform, but each have their own benefits and consequences. I recently gave a presentation at this year’s Community Summit conference on this topic, but in case you missed it, I’ll recap a lot of it here with the best architecture for various common scenarios, how your choices may affect automations/reports/scripts, and how to future-proof your data.
To preface the visuals forthcoming, I’m going to be working from the make.powerapps.com solution interface and displaying components from the UI of a generic model-driven app, but the advice here is applicable to good architecture to any Dataverse-based applications including D365 CE, Canvas Apps, Power Portals, and more.
Tables
When planning your tables, it’s important to be aware of the decisions you’re making that are permanent. You can turn things like auditing on and off at will, but some things can’t be changed later, and some things if you turn them on, you can’t turn them off. These permanent choices are key to get right at the outset, because it can be nearly impossible to fix once you have live data and customizations in them.
Your first test is going to be choosing a good name:
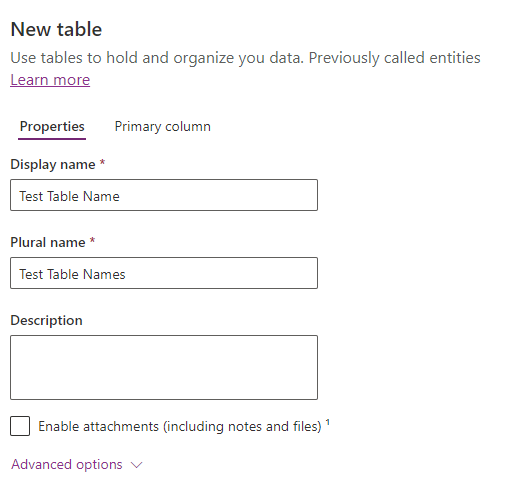
On the plus side, if you get this wrong and pick a name that turns out to be unintuitive, you can change the display name. But, there’s an underlying, un-editable schema name that your developers are going to be leveraging forever:
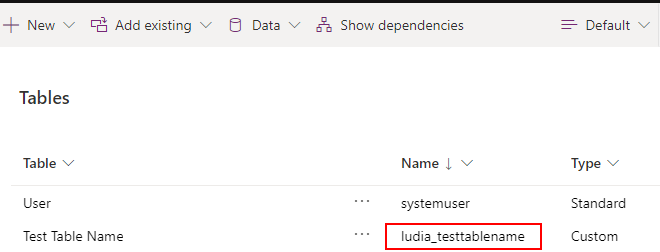
First, note that the Display Name here is generally meant to house the “singular” noun of what you’re trying to store- don’t pluralize until you get to the “Plural Name” box. Secondly, now is the time to think about whether you might want to generalize this down the line or not. Don’t call your new table “Golf Tournament Fundraiser” if down the line you might want to store more kinds of fundraisers in the future. Call it “fundraiser”, or better yet, “event” and categorize it inside. You don’t want all of the code for your nice, general event management system down the line querying a list of “xyz_golftournamentfundraiser” records to find your charity dinner.
If you expand out the “Advanced Options” here, you’ll get to your next set of important decision points:
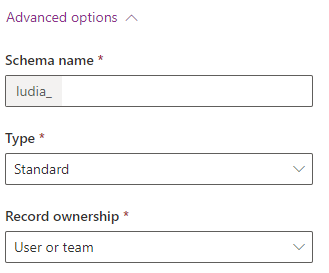
Here, for the “Type” of table you’re going to want “Standard” 99% of the time, but if you might want to make this an “Activity” instead, now is the time to decide. Out of the box, these are things like phone calls, emails, appointments, tasks- things that occur at a point in time and could be regarding various records in the system. The strengths of these are that they can show up on the timeline for a record, and they can also be associated by the “regardingobjectid” field to any entity in the system that you turn on the timeline for. If your table describes something that occurs at a point in time and could occur “about” a wide variety of different types of the tables in your system, this may be the right choice for you.
“Virtual” tables are something different entirely. This one is a much bigger topic for another day, but it’s basically a built-in integration with some other data source. The table’s columns map to columns in another datasource- the data here doesn’t sit in the dataverse at all. It’s a powerful tool, but doesn’t work with anything but the most basic functionality. Rollups, charts, auditing, business process flows, and more don’t work at all, and even filtering, sorting, searching with them is pretty limited in what works and what doesn’t. The main thing to know here though is that this is an integration tool, so if that’s not what you’re looking for, look elsewhere.
The other primary selection to be made here is regarding “Record Ownership”. This one seems complex, but I’ll make it easy- you can feel safe just making literally every entity in the system user-owned, aside from virtual tables (which can’t be). If you have data that you’re completely sure it will never make sense for users to have access to anything but all or none of, you can consider organization ownership, but to future-proof your data, I would say just always pick “User or team”. You can always just hide the owner field on the UI and give users organization level access to the entity and it effectively does the same thing, just minus the headache if you change your mind later.
The last thing to note regarding tables is this warning below:
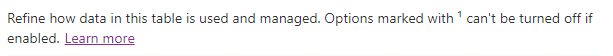
This is because they have a data component to them, once they’re on for a while there’s potentially a bunch of data that’s going to become invalid if you could turn it back off, so the system just prevents you from turning them off at all once they’re on. There are a number of these settings with this marking and I won’t get into the weeds on them here, just make a note that they’re there and consider leaving them off until you’re sure you need them.
Column Data Types
Once you have your table in place, it’s also important to consider what data type to make your columns carefully because these can’t be changed after creation. If you do need to change it, you’ll need to unwind all dependencies and automations that reference it, make a new column, and then transform and migrate all of the existing data. With that in mind, here are a number of the situations that take some thought:
Text Columns
Text columns are the default and most basic type of data you can store, but have a lot more options for them than classic CRM has had in the past. Enough so that they have an entire category for them upon creation:
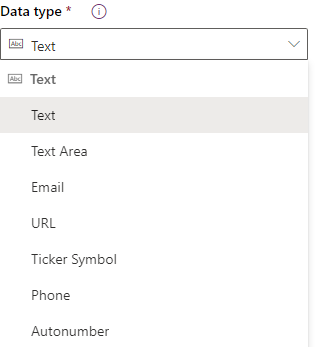
Of these, the option called “Text” is your basic go-to if your text data doesn’t have any other special situations that apply. It can support up to 4000 characters, which is actually fairly large, but is only displayed on a single line (this field was classically called “Single Line of Text”). If your expected input is going to potentially be comprised of a couple paragraphs of data, you may want to consider the next option in the list: “Text Area”. In terms of character limit, it’s identical to the “Text” field, but allows for being rendered as a textbox multiple lines tall. Lastly though, if you think that your input may ever contain more than a couple paragraphs of text, in order to future-proof your data you should likely choose the Multi-Line text option. It looks like a Text Area when rendered, but can support over a million characters as a max length if needed, so you don’t have a data nightmare on your hands if you ever need to allow for more than 4000 characters in the future.
You’ll also notice this category has a large number of other choices we haven’t mentioned yet. URL, Email, Ticker Symbol, and Phone are all effectively the same datatype as “Text” on the backend- they all support text input up to 4000 characters, but have a click-enabled icon at the end of it that launches something relevant to the named datatype. These smartly take you to a hyperlink, a mailto, the stock ticker on MSN money, or your default phone calling app respectively:
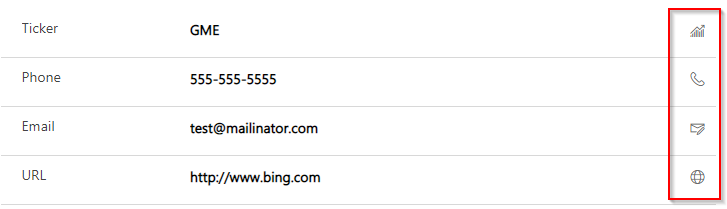
If these apply to your data, you should use them.
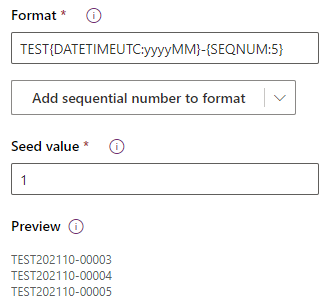
The last type of text field you’ll encounter is the Autonumber field. This is for any kind of data you need a unique value for but don’t need a person to manually maintain. For example, an email isn’t the kind of data for this, but if you just need a human-readable ID number of some kind, it’s a great choice. In addition to the incrementing number, you can add strings, any components of a date, whatever in a very customizable format. If you can use this, you should, otherwise you’re going to need to use a regular text field and build a custom plugin, maintain and update a value in the system, worry about timing and data locking, and it’s a big pain compared to letting the system handle it. Here’s an example of a powerfully customized setup in action:
Numeric Columns
These are actually spread out between the Whole Number section and the miscellaneous area at the bottom. While “Whole Number” is the first numeric option in the list you encounter, in order to future-proof your design, you need to be very careful if you choose this. You’ll want to make sure that if you’re going to pick this, the number couldn’t possibly have a fractional component to it no matter what. For example, you’re not going to have a fractional number of students in a class, so it’s probably the right choice in that situation. But, you might eventually have a fractional quantity of items ordered even if your current inventory is fully discrete- maybe today you only sell pens and pencils, but at some point you might want to sell pounds of sugar.
When you need to use numbers with a potential fractional component, within that space, you have another choice to make:

Between the Decimal Number and Floating Point Number, these look and feel like they do the same thing, so it can feel confusing. Fortunately, the choice between them should be easy- I would suggest just always using decimal. The float is really just there to map directly to the old primitive C# datatypes, and is just going to be worse to work with on the backend.
Lastly, you have a Currency type to choose. It may sound obvious, but if your column is tracking money, you should use this. It may seem like decimal may do the same thing at first thought, but there are a lot of advantages from using the real currency field. It makes it obvious through the UI what type of currency you’re talking about, lets you store the currency type (USD, KRW, etc.), formats nicely, and also gives a powerful apparatus to support exchange rates and normalize amounts in the future if you need to. The currency functionality deserves a blog post of its own to explore, but for the purposes of this post, just making sure to use it when it’s applicable is the primary goal.
Date and Time Columns
Tracking dates is a major headache in all systems because of the existence of time zones and is another topic to dig deeper into in the future, but for today, we’ll touch on the basic choices. At the highest level, the first choice you’re going to make is between “Date Only” or “Date and Time”:

Here, if all that matters is the date, you can pick date only- no need to complicate with time zones and such. Otherwise, if the time is helpful, you can select “Date and Time” and you’ll additionally get this clock component in the Model-Driven UI:

With this version, you’ll additionally have another choice to make:
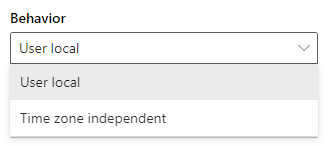
If you’re not sure here, you should default to using User Local (the system in-fact does default to this). This will store the selected time in the database in UTC and convert it dynamically to the time zone in each user’s settings when displaying it to anyone. Alternatively, however, the Time-Zone Independent is a great tool for handling times that should be the same to everyone everywhere. This is effectively like you’ve stored a string of text in the database instead of a real date and won’t perform any conversions. You will probably use this less often, but it’s perfect for things like flight departure/arrival times that should never change based on where someone is looking at the data from.
Selection Columns
These are typically displayed as dropdowns in a model-driven UI, they’re all in the bottom miscellaneous area, and have some important considerations around how to design them. The most basic selection column types here are called “Choice” and “Choices” (formerly called Option Set and Multi-Select OptionSet).
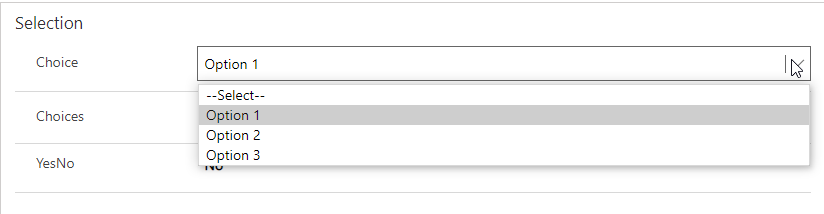
These are basically intended to be pick-one or pick-multiple equivalents to each other. If the choices available are highly unlikely to change over time and all you need is a self-explanatory name of the option, these are a great. For example, a perfect use for a “Choice” (singular) column would be a difficulty selection for a course (e.g., Easy/Medium/Hard). For the “Choices” (multiple) component specifically, it currently has some limitations- if you know you need to use it in business process flows or business rules, you might consider a series of Yes/No fields representing each choice instead.
Yes/No fields are for strictly Boolean (two options) data- you can name the two options whatever you want, but you only get 2. To future-proof your design, you should only use it for data where there could only possibly be 2 options ever, not just when there are only 2 options now. For example, using this to select between Air and Ground shipping is a bad design because you might want to add additional shipping options in the future even if they aren’t available today. Additionally, in code, no matter what you name the options this is still a true/false field, so it’s going to look non-sensical if you’re referring to your shipping types as “true” and “false”. One final consideration is that even if you only expect to ever have 2 “real” choices, if you need the value to be able to be null, you usually still should use Choice instead.
The final main type of column to choose from here is a Lookup. These are used to relate any data in the system N:1, but is also a great alternative to a Choice field under the previously mentioned scenarios in which your available options are expected to change over time, or if you need to store additional data about the option itself. As an example, if you have a table of college courses, you might want to track the college or online education provider delivering the lessons. In theory, you could track these in a Choice column, but would quickly run into trouble as soon as any of the available options were no longer offering classes. You can’t just deactivate an option out of a Choice column the way you can deactivate a record, you would either be stuck with a bunch of obsolete options in your dropdown or invalidating all old data referencing the option. Additionally, if you wanted to track information about each option, such as the address of the institution, this can only reasonably be done with a lookup to a record, not an option on a Choice column.
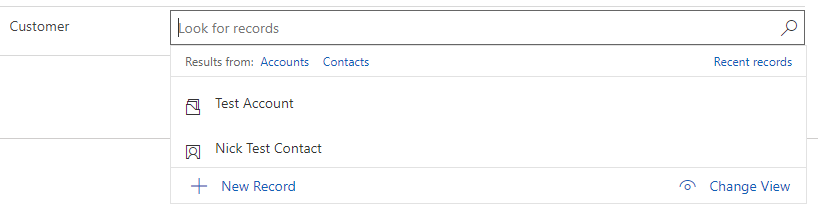
One bonus special type of Lookup you’re able to create, if applicable, is a “Customer” column. This is what’s called a “polymorphic” Lookup that allows for either a Contact OR Account to be populated in the same column. In the first party apps, we see quotes, orders, invoices, cases, etc that leverage these to be applicable to either type of a customer. If you use this, you create more work in your reports and automations to account for both possibilities, but if the record legitimately applicable to either an account or contact (and never both), it makes for a slick design.
Conclusion
When architecting the design for your system, it’s easy to make a system that can house the data you have today, but the mastery is in making sure it’s prepared to elegantly store the data you’ll have tomorrow. Hopefully this post is able to spare you from learning about future-proofing mistakes the hard way! Stay tuned for a part 2 where we dive into the different ways you can handle many-to-many relationships in your architecture.
If you have any questions or would like to learn more, please contact us!